OVERVIEW
Metascript is an open source tool that provides a basic textual analysis framework for the comparison of an original text (novels, short stories, etc.) and its film transposition (screenplays). The goal of Metascript is to provide a set of guidelines for the markup and the metadata enrichment among multimodal texts, such as a book with its screenplay adaptation for audiovisual transposition.
Metascript also enables the alignment of the marked texts with the final visual rendering of the film through the use of timestamps inherited from subtitles files, allowing for the visualization of the different portions of the texts in its different versions, both textual and visual, paired with analysis of the colors and of the scenic rendering of the narrative passage.
The example used as a working prototype for the project is Arthur Schnitzler's novel "Dream Story" and the two screenplays (a '96 draft and a '99 transcript) from the film "Eyes Wide Shut", a transposition of Schnitzler's novel directed by Stanley Kubrick and adapted by Kubrick himself alongside with Frederic Raphael.
The development of Metascript has followed three macro-stages:
- The creation of the XML-TEI encodings of the different texts (with a particular attention for the implementation of Linked Open Data)
- The extraction of relevant data using python scripts
- The analysis of the data and the graphical visualization of the results
Metascript aims to answer the call for the development of a working model of digital textual analysis related to film screenplays, a niche literary class of texts whose digital applications and methodologies have not yet been studied and/or applied thoroughly. Our project wants to stand as an initial model and reference guideline for the encoding of screenplays, and in particular for the ones that spur from the adaptation of more classical literary texts. In this sense, Metascript is set to create an encoding model that connects the different text and audiovisual mediums, aligning elements such as scenes, characters and places between them; for example, characters whose names, gender or other peculiarities have been changed in the adaptation from the book to the screenplay are aligned in a way that allows for the changes to bee tracked among the transmodality of the texts. The same thing is done for paragraphs of the book that have been translated in specific scenes of the screenplay. Metascript enables the reader to navigate these scenes and explore the differences between the original text and its adaptation, from a narrative and textual point of view but also visually, by enabling an easy alignment with the film itself, and its corresponding visual frames.
In addition to XML-TEI tagging and text alignment work, special attention is given to the inclusion of metadata and linked open data.
A further goal of the project is to be able to extrapolate quantitative data from the texts, capable of providing insights on the changes and/or similarities among them. In our prototype, we chose to extrapolate data regarding the relationships between characters through the use of Python scripts. A network analysis of this data has subsequently been produced using libraries such as networkX and Bokeh to concretely visualize the results and answer some research questions.
The same thing was done in relation to geographic data, utilizing the libraries xml.etree and folium.
Finally, one last analysis was performed in relation to the space and time data of the single scenes from the screenplay to quantify the percentages of the scenes that have been shot at night rather than during the day, indoors or outdoors.
The source material
In choosing the working material on which to set our prototype, we conducted extensive research around film transpositions derived from books.
One well-known director who often relied on novels in the creation of his films was Stanley Kubrick. Therefore, we decided to analyze his filmography and trace back to the original texts from which he started his adaptations.
Some of the titles that most attracted our attention were Lolita, Eyes Wide Shut, 2001: A Space Odyssey, Barry Lyndon, and Full Metal Jacket.
Our final choice fell on Eyes Wide Shut and its corresponding novel "Dream Story" (original language "Traumnovelle") for several reasons:
- the availability of the html and txt texts of the screenplay and the book
- the presence of interesting changes implemented by the director in terms of space and time
- the particular use of color and outdoor/indoor spaces in the film
The chosen source materials are:
- the novel "Dream Story" translated by Otto P. Schinnerer from the original German "Traumnovelle" by author Arthur Schnitzler, published by Green Integer (Los Angeles)
- the 1996 draft screenplay of "Eyes Wide Shut" written by Stanley Kubrick and Frederic Raphael
- the 1999 transcript of "Eyes Wide Shut" published on October 1, 1999 by Grand Central Pub (New York)
The ‘96 draft and the ‘99 transcription are very similar, but have some differences on various scenes that were later cut or changed by the director. In addition, the ‘96 draft is incomplete in that it is missing some scenes that were later included in the final version of the film.
Apart from these minor differences in content, the two texts are otherwise formally the same. Respecting the look and layout rules of a film script (capitalized names before each line of dialogue, scene setting introducing the place and light characterizing the moment of the scene etc.). These particularities led us to think carefully about how we could mark this text type correctly and in an efficient way.
The competency questions
Starting from the reading of the source materials, we defined some research questions to better visualize the goals of the project:
- How can we simply and directly compare the various scenes in the film with the corresponding moments in the original book, so as to highlight their fidelity and changes?
- What differences exist at the level of characters and their relationships within the book and the screenplay? What about between the '96 draft and the final '99 version? Do they reflect or highlight changes?
- How does the geographical setting of events change between book and film?
- Which scenes and passages in the book occur during the day, and which occur at night? Do moments set outside in the book remain so in the film, and vice versa?
Workflow scheme
From the research questions posed, it quickly became clear that we needed to follow a clear workflow to achieve our goals step by step.
| Step name | Description | Technologies and tools | Output |
|---|---|---|---|
| Definition of the starting material and objectives + relevant academic literature with similar examples | Search for the book connected to the screenplay (editions and translations). Screenplay research (various drafts and published transcription). Definition of research objectives and relative competency questions. | IMSDb, IMDb, Internet Archive, WorldCat, Academia, JStor |
Starting files. Metadata. Working plan. Idea of the state of the art of the field. |
| Workflow definition + ontologies choice | Definition of the workflow stages + creation of the UML of the project and definition of the ontologies useful for visualizing the creative process | LOVDocumentation |
UML Work scheme Conceptual Map for the Ontologies |
| Transformation in XML-TEI + Markup Model definition | Markup of the texts in XML-TEI + search for the most appropriate tags for the type of material analyzed. Creation of the general markup model adaptable to a film script. | Python script, TEI documentation, Visual Studio Code | File XML-TEI with LOD |
| Data extraction and analysis | Extraction of data, from the XML-TEI files, relating to characters, their interactions, geographical locations, time and space. Creation of csv and json files. Data processing through appropriate python libraries and graphical display of results. | Python libraries used:Bokeh, Plotly, NetworkX, Folium, BeautifulSoup, xml.eTree | Data and graphs |
| Visualization of the XML in html | Creation of three sections for comparing the same scenes/moments in the book, draft and transcription | http request with javascript | Viewing texts on the website |
| Website development | Creation of the website of the application example prototype, suitable for consultation even by less expert users. | html, css, Javascript | Final website for the user |
Data Modeling
After having defined the workflow, we started modeling the data to understand how to formalize all the relationships used inside the project.
The structure of the data model was inspired by the one created for the “National Edition of Aldo Moro’s Works”[1].
We modeled the data starting from the basic element, the RDF statement, constituted by a triple that represents subject, predicate, object. Subject and predicate are always represented by a URI, while the object can be an URI or a literal value.
Then, the formalization offered by FRBR (Functional Requirements for Bibliographic Records) and, consequently, FABiO (FRBR-aligned Bibliographic Ontology) was used to describe the elements of our project as codependent from one another:
- fabio:Work refers to the general concepts of the book “Dream Story” and of the movie transposition “Eyes Wide Shut”.
- fabio:expression, the intellectual content, in our case is the translated version of the book, the draft screenplay and the transcription of the movie.
- fabio:manifestation is the materialization of the entity, in our case the book version that has been published by Green Integer, the XML-TEI encodings, the transcription of the movie published in 1999 and the draft screenplay.
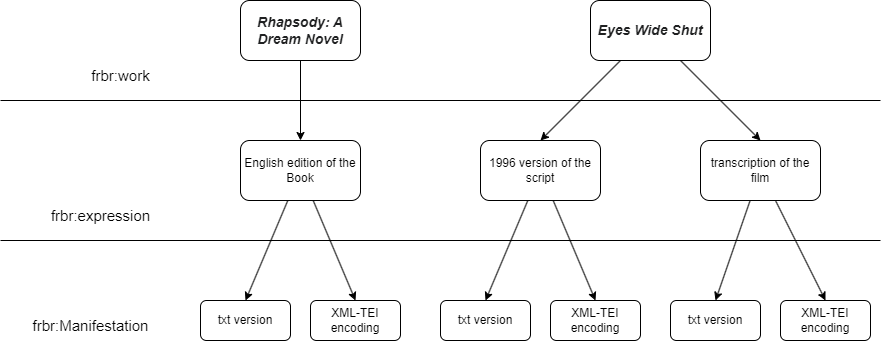
We chose to use FABiO as the core ontology for this project because it describes “entities that are published or potentially publishable, and that contain or are referred to by bibliographic references, or entities used to define such bibliographic references”[2].
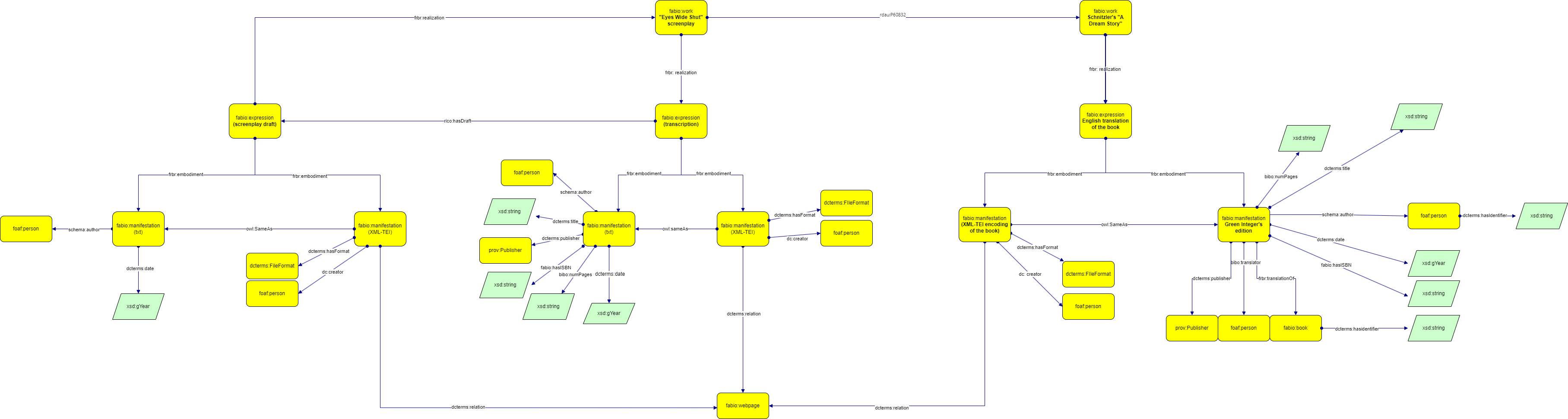
We used other ontologies to formalize the relationships between the entity and its metadata or between entities as shown in the table below.
| Ontology | Documentation | Properties or classes used |
|---|---|---|
| FABiO | https://sparontologies.github.io/fabio/current/fabio.html | fabio:Work, fabio:Expression, fabio:Manifestation, fabio:hasISBN, fabio:book, fabio:webpage |
| FRBR | https://vocab.org/frbr/core | frbr:embodiment, frbr:realization, frbr:translationOf |
| FOAF | http://xmlns.com/foaf/0.1/ | foaf:person |
| PROV-O | https://www.w3.org/TR/prov-o/ | prov:publisher |
| dcterms | https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ | dcterms:date, dcterms:title, dcterms:source, dcterms:publisher, dcterms:hasFormat, dcterms:hasIdentifier, dcterms:FileFormat |
| dc | https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ | dc:creator |
| BIBO | https://www.dublincore.org/specifications/bibo/bibo/bibo.rdf.xml# | bibo:translator, bibo:numPages, |
| schema | https://schema.org/ | Schema:author |
| RDA | http://www.rdaregistry.info/ | rdau:P60832 |
| OWL | https://www.w3.org/2002/07/owl | owl:sameAs |
Then, we have used the tool Graffoo to render graphically our model.
XML-TEI ENCODING
The next step was the encoding of the three texts using XML-TEI. XML is a metalanguage, a basis for other standards and can be easily transformed in another format. TEI is used for the digital representation of texts and its specifications allow the encoding of different types of text (i.e., screenplays, novels, poetry). The goal of the XML-TEI is to encode the texts both from a logical and a semantic point of view, using tags to make explicit the structure of the text and add metadata that can be useful for a standardized and immediate interpretation, but also to extract information and analyze it.
The TEI header
The TEI header serves as a repository for metadata related to the encoded text. In our project, the TEI header consists of three main sections:
- <fileDesc>:This is a mandatory section that provides a description of the TEI file. It comprises the following subcomponents:
- <titleStmt>: This section contains information about the title of the text and its author.
- <publicationStmt>: Here, details about the publisher and the date of publication are included.
- <seriesStmt>: This section contains information about the series to which the book belongs.
- <sourceDesc>: This part is used to convey information regarding the resource, specifically the TEI encoding. It includes a comprehensive description of who was involved in the encoding process and the main project's details.
- <profileDesc>: This section provides information about the language used in the text, the locations mentioned, and the characters involved in the narrative.
- <settingDesc>: Within this part, a list of locations is included using the <listPlace> tag. Each <place> has been assigned an ID, and its type (e.g., building, street, city, region, state, park) is specified. The type of designation is valuable for spatial analysis, as it helps determine whether the location can be represented individually or by highlighting an area. The <placename> tag specifies the name used in the text to refer to that location, and in some cases, the corresponding GeoNames URI is added as an attribute to this tag. The <location> tag provides additional geographical information about the location, including the settlement type (e.g., city) and country. The <geo> tag is used to express the coordinates of the location. Occasionally, the <desc> tag is employed to convey additional information about places mentioned in the text, especially considering that the book was written in the early 20th century and some specific buildings, cafes, or hotels mentioned may no longer exist. In such cases, coordinates are added based on the annotated edition of Traumnovelle[3].
- <particDesc>: This section contains a list of all the characters mentioned in the text.
- <listPerson>: Serves as a container for individual character items represented as "person" elements, each with a unique ID.
- <persName> : This tag specifies the name of the character. Additionally, gender information is provided when available, using the "sex" attribute within the <person> tag. If applicable, the <age> tag is used to include further details about the character's age. Physical descriptions of the character or notes regarding parental or social relationships between characters are also included. The same structural organization is employed in a macro-XML file called "characters.xml," which is essential for aligning character names between the original text, draft screenplay, and transcription.
- <xenodata>, a tag used to insert non-TEI elements, in this case we have used it to add Linked Open Data inside the XML in RDF format. The goal here is to combine the document-centric point of view, typical of XML-TEI and traditional digital scholarly editions, with the data-centric point of view, that characterizes the semantic Web[4].
- <rdf:RDF>, the tag specifies the opening and closing line of RDF triples. In the opening tag, all ontologies and metadata standards used in the triples are included as attributes.
- <rdf:Description rdf:about="">tag refers to the document, considered here as a fabio:Item, as the subject of the triple, followed by additional tags expressing the predicate and object. Moreover, other xenoDatatags have been added to describe the different FRBR levels, each of those identified with a URI that points to the RDF/OWL document, in which the conceptual structure of the data model has been formally represented. While the predicate is always associated with an authoritative ontology, the object can be a literal or a URI resource derived from a thesaurus or authoritative coding system. Moreover, triples have also been inserted to trace the subject back to its entity expressed in the project’s data model and to express relationships between entities. Triples using the predicates rdau:p60832 ("is inspired by") and rdau:P60833 ("is inspiration for") were also inserted to describe the internal relationships between the XML files of the original novel and film scripts.
Book Encoding
To encode the information found on the first page, we utilized the <front> tag, specifying that it concerns the <titlePage> of the book. Within this section, the <docTitle> tag serves to contain details about the book's title, while the <byline> tag holds the primary statement of responsibility.
Each chapter within the book is divided using a <div> tag, along with specifications for its type and sequential number. In cases where text portions, which may or may not align with chapters, relate to scenes from the '99 transcription, we include a tag to label them with a type attribute set to "scene" and an "n" attribute to correspond to the scene in the transcription. Furthermore, each portion is uniquely identified using an id attribute. This division is crucial for creating a direct comparison among the three texts on the website and is aligned in a macro-XML file known as "alignment.xml".
To mark citations in the text, we manually inserted the <quote> tag where appropriate. We employed a generic <rs> tag, followed by an attribute specifying the type of person mentioned, such as character or real person, along with an id to uniquely identify the character referenced in the book.
For dialogues, we employed the <said> tag, providing specific attributes:
- "aloud" is set to true if the speech is said out loud, and false if it is not.
- "direct" indicates whether the speech is presented in a direct or indirect manner.
- "who" refers to the speaker.
- "toWhom" identifies the listener.
Multiple speakers or listeners are added as a single string and separated with a comma.
Screenplay Encoding
Being screenplays already loosely schematised texts, we were able to develop a set of scripts to help automate the process of mark-up. This was achieved with the use of the BeautifulSoup library to deal with the original files (an html file for the 1996 screenplay and a txt file in the case of the transcription) which have been parsed using regular expressions to identify patterns in the files that were subsequently translated in the respective XML/TEI-compliant tags for each one of the descriptive elements of the screenplays and for the additional metadata elements. These scripts were able to cut the time that would have been spent manually encoding the texts by a lot; unfortunately, the original screenplay files found on the internet were not flawlessly formatted, presenting many errors in the layout of the pages. This effectively decreased the efficiency of the parsing scripts, as we were forced to correct these sporadic errors by hand after the encoding of the whole files.
In the case of the screenplay of the movie's transcription, we were able to enrich the TEI encoding of the text by adding a timestamp related to the start and to the end of each of the speech tags of the text as they appear in the movie itself. These timestamps were automatically extracted, using again a Python script, from a subtitle file for the movie, which has been parsed and matched with each of the "sp" elements of the marked-up file using the TheFuzz library for fuzzy string matching.
The final screenplay encoding adheres to the guidelines provided by the TEI consortium for correctly tagging performance texts[5][6].
In the header, the "front" tag is employed to store information about the cast members within the <castlist>, with each cast member's details enclosed within a <castItem> tag. For each <castItem>, the character's name is defined using the <role> tag, and a concise description is included using <roleDesc>. To specify the actor portraying the character in the film, the <actor> tag is used, and each tag contains a reference to the unique identifier provided by IMDB. The information contained within the "actor" tag was automatically extracted using a script, significantly reducing the time required for this task. This Python script leveraged the IMDb library to retrieve the names of all cast members involved in the film adaptation, along with their respective roles. Subsequently, this data was saved in both CSV and JSON formats for further use.
Every scene is tagged with a <div>, indicating its type and scene number, along with a unique identifier. If a scene corresponds to one or more scenes in the transcription, an additional <div> is added, containing information about which scene(s) in the transcription match the given scene.
Stage directions are marked using the <scene> tag and feature various attributes:
- "environment" specifies whether the setting is internal or external.
- "primary_location" denotes the general location of the scene.
- "secondary_location" provides more specific location details, such as a particular room.
- "time" conveys information about the temporal setting of the scene.
Additional stage directions are also included using the "stage" tag but with distinct attributes:
- "setting" offers further details about the scene's setting.
- "delivery" is employed when the director provides directions on how the scene should be performed by the actor.
Each line of dialogue is tagged as follows:
- The line is enclosed within a <sp> tag, which specifies the speaker and listener using the same attributes as those employed in the book.
- In the transcription, the<timeline> tag specifies the start and end running times of the line.
- The <speaker> tag identifies the speaker.
- The <p> tag contains the actual dialogue line.
Macro-XML
We have chosen to create two additional XML files, namely "characters.xml" and "alignment.xml," to facilitate the alignment of characters and narrative correspondences among the three texts.
For character alignment, we have compiled lists of characters that were previously defined in the TEI headers of the texts. These character lists are combined in "characters.xml." All correspondences between different characters are encapsulated within a element. The tag is employed to establish hypertextual associations, in this case, aligning the character IDs from the book with their counterparts in the draft screenplay and transcription.
Regarding the alignment of narrative correspondences, we based it on the transcription as the primary text from which we derived the others and identified relative correspondences. We divided the book into sections using a <div> element, corresponding to scenes in the transcription. Each section was assigned a unique identifier (ID) that corresponds to a specific portion of text. The same process was applied to align the draft screenplay with the transcription.
In the XML file, we used tags, as mentioned previously, to align the IDs of corresponding scenes among the three texts. When it is possible to compare only two texts due to a lack of correspondence in the third, the text without the relevant correspondence is omitted.
ANALYSIS
The objective of the analyses conducted in this project is to facilitate the comprehension of dispersed information within a text, while also helping the comparison of the three core texts under analysis. This is crucial for gaining an immediate understanding of how the adaptation has evolved from the original, encompassing not only stylistic changes but also alterations in setting and character interactions. We have opted to perform these analyses because they enable a simultaneous reading and comparison that may not be readily apparent if only one of the texts is read.
The analyses that we have chosen to conduct are the following[7]:
- Spatial analysis of the places mentioned in the book and in the transcription of the movie.
- Network analysis, analyzing the network of characters’ interactions between the three texts.
- Spatio-temporal analysis of the transcription, analyzing which combination of environment-time is more used in the text.
Spatial Analysis
The main goal in doing a spatial analysis in this project was both to visualize and compare the places in which the book and the screenplay take place. In our case “Traumnovelle” and “Eyes Wide Shut” are set in two different cities, and in the movie, the places in which scenes take place are not specified. This tool can be more useful if in both texts there are specifications about the settings, and in this way the differences are more relevant and useful for a comparison. The goal of this script is to automate as much as possible the creation of the map, automatically adding circles corresponding to city areas and points to other types of geographical elements[8]. Unfortunately, there is still the need to manually insert GeoJSON files corresponding to regions, states, or country areas that we want to display on screen.
The python libraries needed to extract information from the TEI document and visualize them inside a map are respectively xml.etree and folium.
xml.etree is used to progressively search into the hierarchical structure of the XML-TEI document. In this case we need to search inside the TEI header the content inside the tag . Then we create a dictionary in which the content of and of the attribute "type" constitute a tuple that represents the key of the dictionary, while the coordinates are the value of the dictionary.
Folium leverages the Leaflet.js JavaScript library to generate maps directly in a Python environment. It is used here to create the map, manually specifying the focus on a specific area from which we want to start our visualization. Through an iteration inside the dictionary, if the 'type' attribute corresponds to 'city', a circle is drawn around the coordinates defined in the XML-TEI document, if it is not the case, then only a point is added in correspondence of the value of the dictionary.
Considering that we want to visualize the areas corresponding to regions/countries/states, we need to find the corresponding GeoJSON files and manually load them one by one into the map.
Then, we save the map as an html file that can be embedded inside the main website for visualization.
From the analysis we can conclude that Schnitzler set the book mainly in Vienna and was extremely precise from a spatial point of view, mentioning specific cafes, hotels and relevant locations within the city. On the other hand, in the adaptation, Kubrick sets the scene in New York and doesn’t delve into much details about the actual locations, he generally mentions a general setting (i.e. a costume shop), without specifying its exact location. Consequently, in this example, we can readily discern the contrasting city settings, but we are unable to make similarly detailed comparisons for specific locations within the story.
Network Analysis
The goal in doing a characters network analysis is to analyze the number of interactions that the characters have inside the story, and simultaneously do a comparison between interactions in the story, draft screenplay and the transcription of the screenplay (1999).
For each of the XML documents analyzed we have created the following: a CSV file containing the interactions; a static graph; an interactive graph.
The libraries needed to extract information from the TEI document, visualize it in a static graph and then in a dynamic one are: xml.etree, NetworkX, Bokeh.
xml.etree is used to search inside the TEI header the content inside the tag "said" or "sp" and get all the information contained in the tags “who” and “toWhom”. This process is done for each "said" or "sp" tag and then the information is added in a list. The script finds if speakers or listeners are more than one (so separated by a comma), splits them, adds them into a list. A dictionary is used to store the number of times the characters interact with each other, counting the number of times the tuple is inside the list.
Then, we store the data into an external CSV file.
NetworkX is used to visualize the data extracted from the XML-TEI in a static network graph. The data previously created is stored in CSV files and is now used to create a data frame using pandas library. Then data inside the columns "Character" and "Listener" are transformed into nodes and their relationship through edges by the library. Labels are added to clearly visualize the relationships between speaker and listener.
Values are then sorted in a descending order, highlighting the characters that have more interactions inside the text, then a bar graph has been created to visualize the 10 characters that have interacted the most throughout the narration.
Bokeh
In the pursuit of crafting interactive visualizations for the network analysis graphs of the three distinct texts, we adopted the Python library Bokeh. Bokeh stands out for its extensive customization capabilities, offering an array of plots tailored to specific needs. Using as inspiration the procedural steps outlined in Introduction to Cultural Analytics and Python[9], we undertook our project with Bokeh, exploiting the data sourced from CSV files containing character relationships in the texts. Bokeh's remarkable versatility enabled us to thoroughly tailor the graphical representations to our precise requirements. Subsequently, we saved the resulting visualizations as HTML files, making them readily deployable for online uploading. Furthermore, Bokeh's inherent functionality empowers external users to dynamically manipulate the visualizations and export them in PNG format to their local devices.
Our analysis yielded insights into the evolution of character nomenclature and interaction networks across various adaptations of the original literary work. Notably, we observed that character names underwent significant modifications, 'americanizing' several character names to align with a global audience, particularly in the case of key protagonists. To illustrate, an examination of Arthur Schnitzler's "Dream Story" revealed a narrative characterized by a relatively modest cast of characters, with the majority of relationships converging upon the central figure, Fridolin. In contrast, an analysis of the 1996 screenplay draft demonstrated a deliberate expansion of character relationships and dialogues, accompanied by the introduction of numerous secondary characters. Furthermore, this adaptation witnessed a noteworthy process of name adaptation, 'americanizing' several character names to attract an international audience. The final 1999 script transcript marked the climax of narrative expansion, as a plethora of secondary characters orbited around the principal character, Bill, who emerged as the central storytelling focal point. Only a select trio of characters (Alice, Milich, and Nick) established secondary relationships that did not intersect with our central protagonist. This exploration not only underscores the malleability of character names in adaptation but also elucidates the dynamic transformations and amplifications of interpersonal networks within the context of literary adaptations.
Spatio-Temporal Analysis
This analysis gives an idea of the prevalent time and space setting, extracting the stage directions that the director had written on the screenplay. The libraries needed to extract information from the TEI document and visualize graphically the data are: xml.etree and Plotly.
xml.etree is used to search inside the TEI header the content inside the tag "stage" two specific attributes which content is stored in lists. A list of tuples is created, where each tuple contains the information of time setting and related environment. We iterate over the list, and use a dictionary to count the occurrences.
Plotly is a library used to create interactive graphs based on the data that we have extracted before. In this case we wanted to represent our data with a pie chart that represents the percentage of space/time settings. The values of the dictionary, so the occurrences, are stored into a list, and then automatically transformed into percentage values.
This analysis concludes that the prevalent setting of the movie is in an internal space at night.
WEB APPLICATION DEVELOPMENT
The web application built to showcase the project has been developed with HTML, CSS and Javascript and has been hosted, alongside all the material which has been used and crafted for the project, and deployed on Github thanks to Github Pages.
The website serves as a display of the project's capabilities, demonstrating many different kinds of applications that the encoding methodology previously presented can accommodate. Other than hosting the present documentation and the page in which the different analyses are displayed, the webpage also offers a parallel visualization of the three texts, which can be explored scene by scene and compared simultaneously. This was achieved thanks to XML's querying capabilities through the use of XPath selectors, which fetch the portion of the texts corresponding to the scene selected by the user other than also fetching and displaying the corresponding screencaps from the movie, which are also uploaded and aligned in the resource.
We've also developed a script using the moviepy and imageio libraries to facilitate the extraction of frames from the movie scenes. The script is structured into several sequential steps for efficient processing. In the initial step, utilizing regex, we focus on creating and saving a CSV file. This CSV file contains all the subtitles sourced from the XML screenplay document, along with their respective dialog start and end timestamps.
Moving to the second step, we employ the ffmpeg_extract_subclip method from moviepy for processing the full-length MP4 video file and extract a clip of our choice. Users have the flexibility to extract a specific clip of interest by inputting the desired subtitle ID. After saving this chosen clip as a new MP4 file, we can apply the final step to that one only, significantly shortening the analysis time.The last step entails using imageio to capture and save frames from the selected clip in image format. Users also have the option to customize the number of frames to be extracted from the clip, as well as the temporal intervals between each frame.
CONCLUSIONS AND FUTURE DEVELOPMENTS
Throughout the project, we have had the opportunity to assess the challenges associated with XML markup, particularly in the context of film scripts. Additionally, during the data analysis phase, we have observed how changes in spatial settings, temporal elements, and character relationships have influenced the adaptation of the audiovisual content. The Metascript markup model is designed to serve as a versatile and open-source prototype. It can be easily adapted for use with other source materials, including screenplays and original novels, in future projects. Furthermore, the potential for textual comparison can be expanded by delving into the development of sentiment analysis and color analysis for film frames[10]. We aspire to incorporate these enhancements into the future evolution of Metascript.
NOTES
[1] https://aldomorodigitale.unibo.it/about/docs/models#rdf-section.
[2] https://sparontologies.github.io/fabio/current/fabio.html.
[3] Schnitzler Arthur and Michael Scheffel. 2012. Traumnovelle : Reclams Universal-Bibliothek. Ditzingen: Reclam Verlag. https://public.ebookcentral.proquest.com/choice/publicfullrecord.aspx?p=5800094.
[4] Daquino, M., Giovannetti, F., & Tomasi, F. (2019). Linked Data per le edizioni scientifiche digitali. Il workflow di pubblicazione dell’edizione semantica del quaderno di appunti di Paolo Bufalini. Umanistica Digitale, 3(7), p.50-51. https://doi.org/10.6092/issn.2532-8816/9091.
[5] https://tei-c.org/release/doc/tei-p5-doc/es/html/DR.html.
[6] https://quod.lib.umich.edu/cgi/t/tei/tei-idx?type=pointer&value=DROTH.
[7] The analyses conducted were inspired by a project focused on film scripts that can be found here: https://github.com/AdeboyeML/Film_Script_Analysis.
[8] The process of analysis and tools used are taken from Introduction to Cultural Analytics :https://melaniewalsh.github.io/Intro-Cultural-Analytics/07-Mapping/00-Mapping.html.
[10] As for the color analysis, an interesting project has been developed in this website: http://cinemetrics.fredericbrodbeck.de/old. Guidelines for developing this additional analysis: https://towardsdatascience.com/image-color-extraction-with-python-in-4-steps-8d9370d9216e.
BIBLIOGRAPHY
- Barzaghi, Sebastian. (2021). Data modelling in the National Edition of Aldo Moro's works (2.0.1). Zenodo. https://doi.org/10.5281/zenodo.5524746 .
- Daquino, M., Giovannetti, F., & Tomasi, F. (2019). Linked Data per le edizioni scientifiche digitali. Il workflow di pubblicazione dell’edizione semantica del quaderno di appunti di Paolo Bufalini. Umanistica Digitale, 3(7). https://doi.org/10.6092/issn.2532-8816/9091.
- Flanders, J., Jannidis, F. (2019). The Shape of Data in the Digital Humanities. Modeling Texts and Text-based Resources. Oxon:Routledge.
- Kubrick, S., Raphael, F. (1999). Eyes Wide Shut: A Screenplay & Dream Story. Los Angeles: Grand Central Pub.
- Schnitzler, A., Schinnerer, O.P. (2003). Dream Story. København: Green Integer.
- Vitali-Rosati, Marcello. (2018). On Editorialization. Structuring Space and Authority in the Digital Age. Amsterdam: Institute of Network Cultures (Theory on Demand 26). DOI: https://doi.org/10.25969/mediarep/19245.